![[NAFNet Review] Simple baseline for restoration](https://cdn.hashnode.com/res/hashnode/image/upload/v1658417902005/lch1WVIPd.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)


Article
Chen, Liangyu, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. "Simple baselines for image restoration." ECCV 2022.
Method
This paper conducted extensive experiments and found that by replacing some items that are for long applied by many baselines with simplified items, the performance of image restoration could be "surprisingly" improved. These mechanisms can be tried in our own tasks. The involved items are also comprehensive, which include rescaling, channel-wise attention, non-linear transform, and the selection of normalization.
Feature rescaling
TransposeConv can easily produce checkerboard artifact, and therefore is replaced with Bilinear interpolation or PixelUnshuffle. StridedConv can break the Nyquist Sampling Theorem, and therefore is replaced with Bilinear interpolation or PixelShuffle.
Simplified Channel Attention
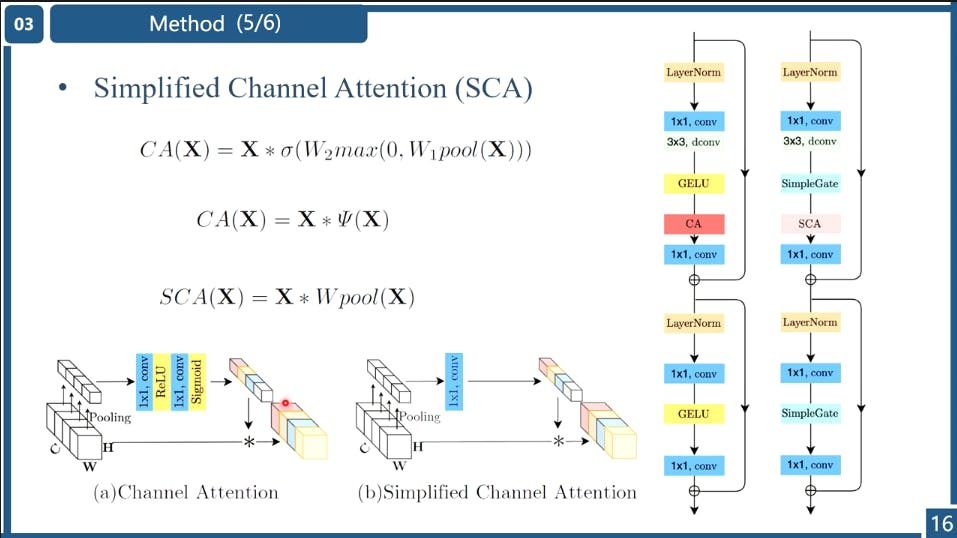
The authors found that the non-linear transforms are redundany and can be removed. Hmmmmm, another empirical finding.
# Simplified Channel Attention
self.sca = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels=dw_channel // 2, out_channels=dw_channel // 2, kernel_size=1, padding=0, stride=1,
groups=1, bias=True),
)
Non-linear transform
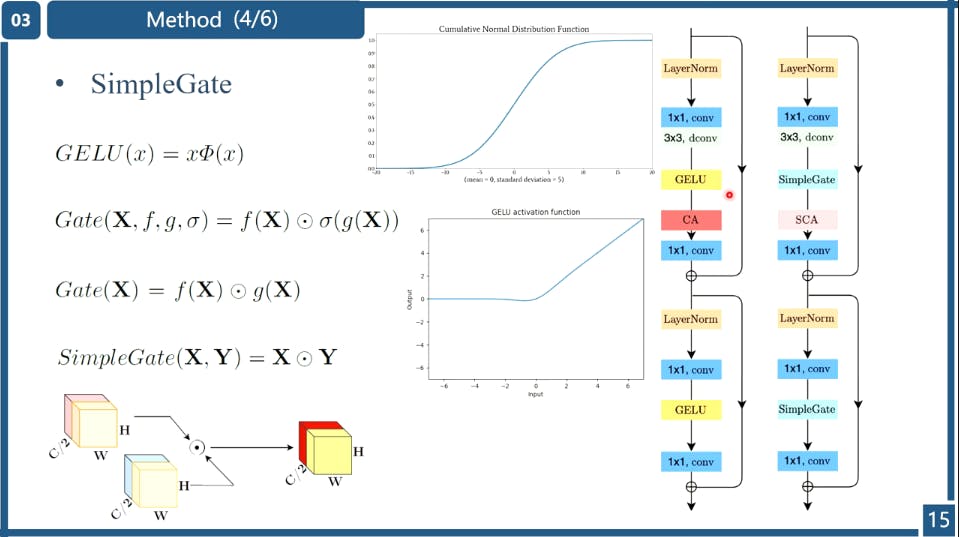
Normally, we use ReLU, ELU or Leaky ReLU in our code as non-linear transform. Some papers also try using GELU, which has been made popular by the Transformers. The authors did not use GeLU, but use GLU, which is Gated Linear Units. The reason is as follows: (an empirical finding)
We find that in these methods, Gated Linear Units9 are adopted. It implies that GLU might be promising. We will discuss it next. Through the similarity, we conjecture from another perspective that GLU may be regarded as a generalization of activation functions, and it might be able to replace the nonlinear activation functions. Even if the σ is removed, Gate(X) = f(X) ⊙ g(X) contains nonlinearity.
class SimpleGate(nn.Module):
def forward(self, x):
x1, x2 = x.chunk(2, dim=1)
return x1 * x2
The selection of Normalization
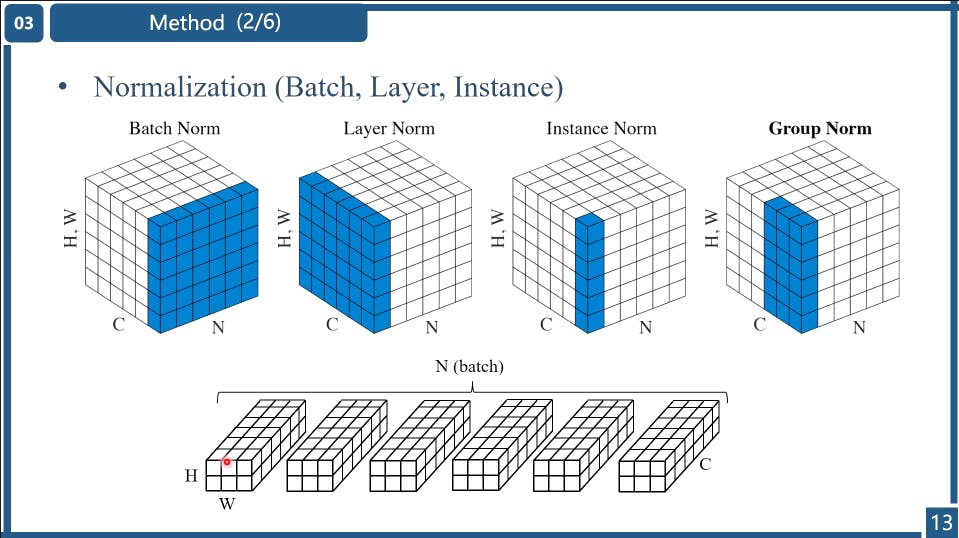
In the paper, the authors found that using LN is better in performance. LN is also widely used in Transformer-based networks. Maybe items used in CNNs can be all replaces with the counterparts used in the Transformer??
Based on these facts we conjecture Layer Normalization may be crucial to SOTA restorers, thus we add Layer Normalization to the plain block described above. This change can make training smooth, even with a 10× increase in learning rate. The larger learning rate brings significant performance gain: +0.44 dB (39.29 dB to 39.73 dB) on SIDD[1], +3.39 dB (28.51 dB to 31.90 dB) on GoPro[25] dataset. To sum up, we add Layer Normalization to the plain block as it can stabilize the training process.
Take-aways
I think this paper is interesting in the network design. The writing of this paper is more like a blog. The authors step-by-step showed his hypothesis, implementation and performance gain of replacing each item listed above. It is surprising that by removing those things which seem to be irreplacable such as GELU/ELU, the performance could be even better. However, it is not certain whether these findings can be applied to many more tasks.