

![[DeepMIH Review] Recursive INN and Importance Map](https://cdn.hashnode.com/res/hashnode/image/upload/v1657954730415/e_Ma_tSK1.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)


Article
Guan, Zhenyu, Junpeng Jing, Xin Deng, Mai Xu, Lai Jiang, Zhou Zhang, and Yipeng Li. "DeepMIH: Deep Invertible Network for Multiple Image Hiding." IEEE Transactions on Pattern Analysis and Machine Intelligence (2022).
Method
The motivation of this paper is to hide multiple images into a single image. The code is available on Github.
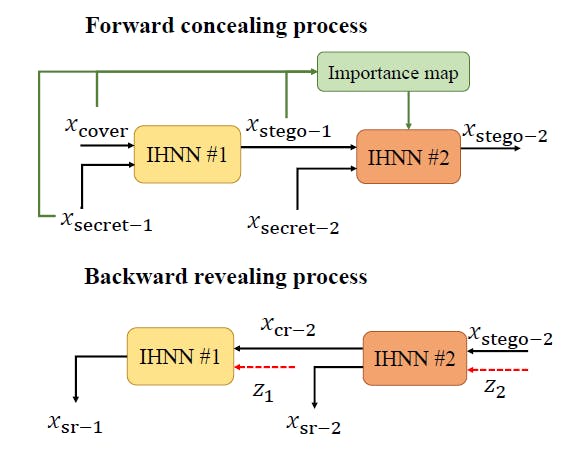
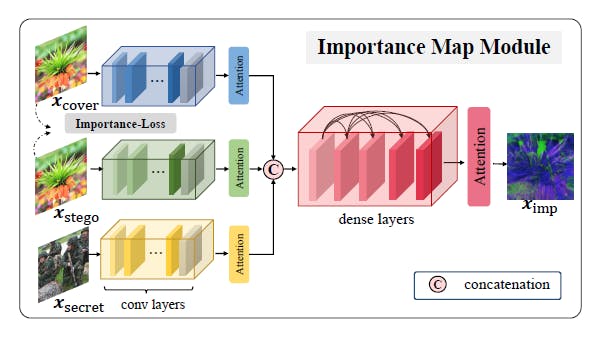
The INN network used in this paper is based on the famous RealNVP, with only trivial modifications. The importance map can be a contribution, which can inform the subsequent INN networks of extra information that can hardly be extracted from the input (hmmmmmm, which is the hidden residual, I guess)
Take-aways
The paper is with plenty of experiments. Besides, the importance map can provide extra information to the network. It serves as a manual bias, allowding marked image of the previous stage to be viewed as a new original image.
However, theoretical analysis is missing, since this paper is accepted by TPAMI? Can we introduce more "importance maps" in other computer vision tasks? Or is there any similar mechanisms?
Useful codes
I found nothing special in the design of training process or network architectures.
The following code is how to calculate "low-frequency wavelet loss" in the paper. Actually it can be replaced with multiple other losses, such as the famous SSIM loss, or the representation can be calculated using Haar Transform or through Bayar Conv.
def dwt_init(x):
x01 = x[:, :, 0::2, :] / 2
x02 = x[:, :, 1::2, :] / 2
x1 = x01[:, :, :, 0::2]
x2 = x02[:, :, :, 0::2]
x3 = x01[:, :, :, 1::2]
x4 = x02[:, :, :, 1::2]
x_LL = x1 + x2 + x3 + x4
x_HL = -x1 - x2 + x3 + x4
x_LH = -x1 + x2 - x3 + x4
x_HH = x1 - x2 - x3 + x4
return torch.cat((x_LL, x_HL, x_LH, x_HH), 1)